How to setup a Sitecore Search feed crawler + Product feedback
The Sitecore Search feed crawler features are described in the documentation. On the other hand, while I tried to set it up on my own, I faced a few gaps. This blog note is about how to setup a feed crawler. To make it interesting, I used ChatGPT to first find if it gives any useful results and in my case, it seemed irrelevant since it doesn't go into details of setting up SFTP for a CSV or JSON file since that is the crux of the feed crawler:
ChatGPT - How to setup feed crawler?
Sitecore Search Feed Crawler Process:

Purpose:
The feed crawler is useful in scenarios where you want to decouple the content and then feed that content to the crawler for indexing. In the current world of DXP and third-party integrations, the feed crawler seems to me the most useful utility. Note that the Sitecore Search feed crawler works only with files uploaded to the Search domain upload directory (called as base path in feed crawler parlance) and doesn't work with external stand-alone urls. The feed crawler can extract from JSON and CSV files. It can also accommodate zip file with one of the file types.
Pre-requisites:
2. You need the sftp server details of where to upload the files for your search domain. You can receive this from the Sitecore Support team. The sftp server details look like this:
- Host: sftp.rfksrv.com
- Username: 18246680
- Password: g288ec196bd909g03d1
Upload file:
Since this is a test-drive, I decided to keep this csv file in alignment with the content entity.
content.csv:
SFTP setup:
Although, you can connect to the ftp server from windows via Add Network location, this wouldn't work since its an SFTP connection and you will end up with an FTP folder error detailed as "A connection with the server could not be established":

Unless you have a way to pass both username and password as part of connecting to sftp, the windows network connection is not useful. On the other hand, the time-tested approach is to use filezilla client. Once you have fileZilla client, you can provide the host name, user name and password then ensure to pass port as 22 since this is an sftp connection:
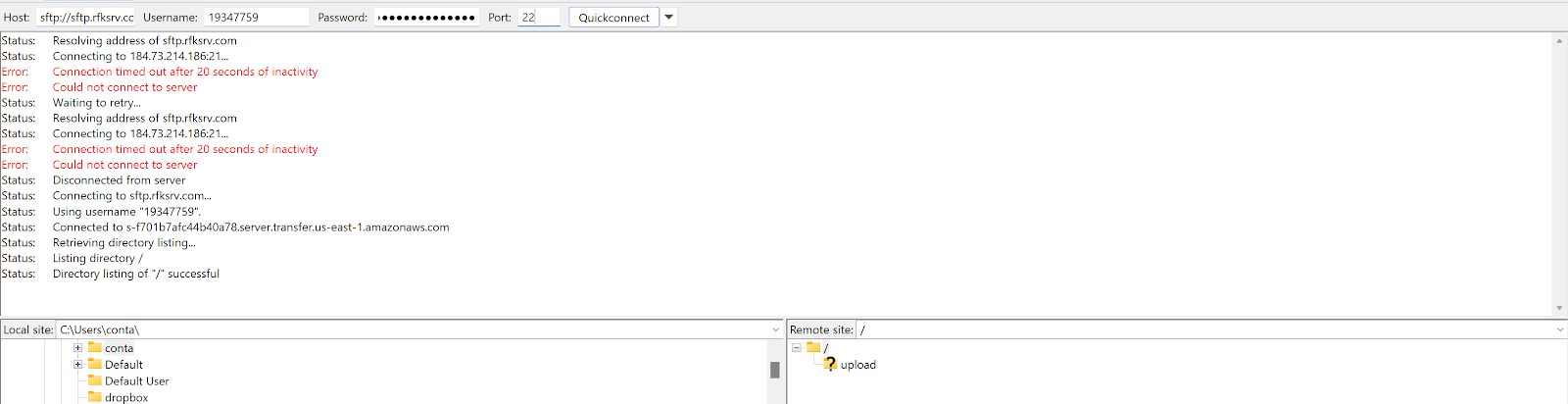
Crawler setup:
The Sitecore Search feed crawler needs files to be uploaded to upload folder in the Sitecore Search ftp server specific for the domain. Once the file is ftp-ed to the upload folder or its sub-folders, the crawler would be able to access the upload folder and its sub-paths specified in the Document Extractors Basepath.
Source Information:



Tags Definition:


Taggers:



In case of transformation, the html escape and unescape is used mainly in case of html-encoded strings like & in fields like description that is part of JSON feed. Based on the type (escape/unescape), the parser does the needful.

Clicking the bar in the graph gives more detailed information:

You can also check the individual indexed content from the content collection section:



Comments
Post a Comment