Expose REST API via ngrok for Sitecore Search API Crawler Walkthrough + Product Feedback
The Sitecore Search API crawler is useful as part of consuming external API data and presenting indexed search results. I decided to see this in action by setting up a REST API with CRUD operations locally and consuming the same a.k.a bootstrapping the API crawler. As ever, I came across some unique scenarios and had to troubleshoot the same and hence this blog post. I picked up a random Student API project that uses EF Core from github so that it would be interesting to integrate with Sitecore Search.
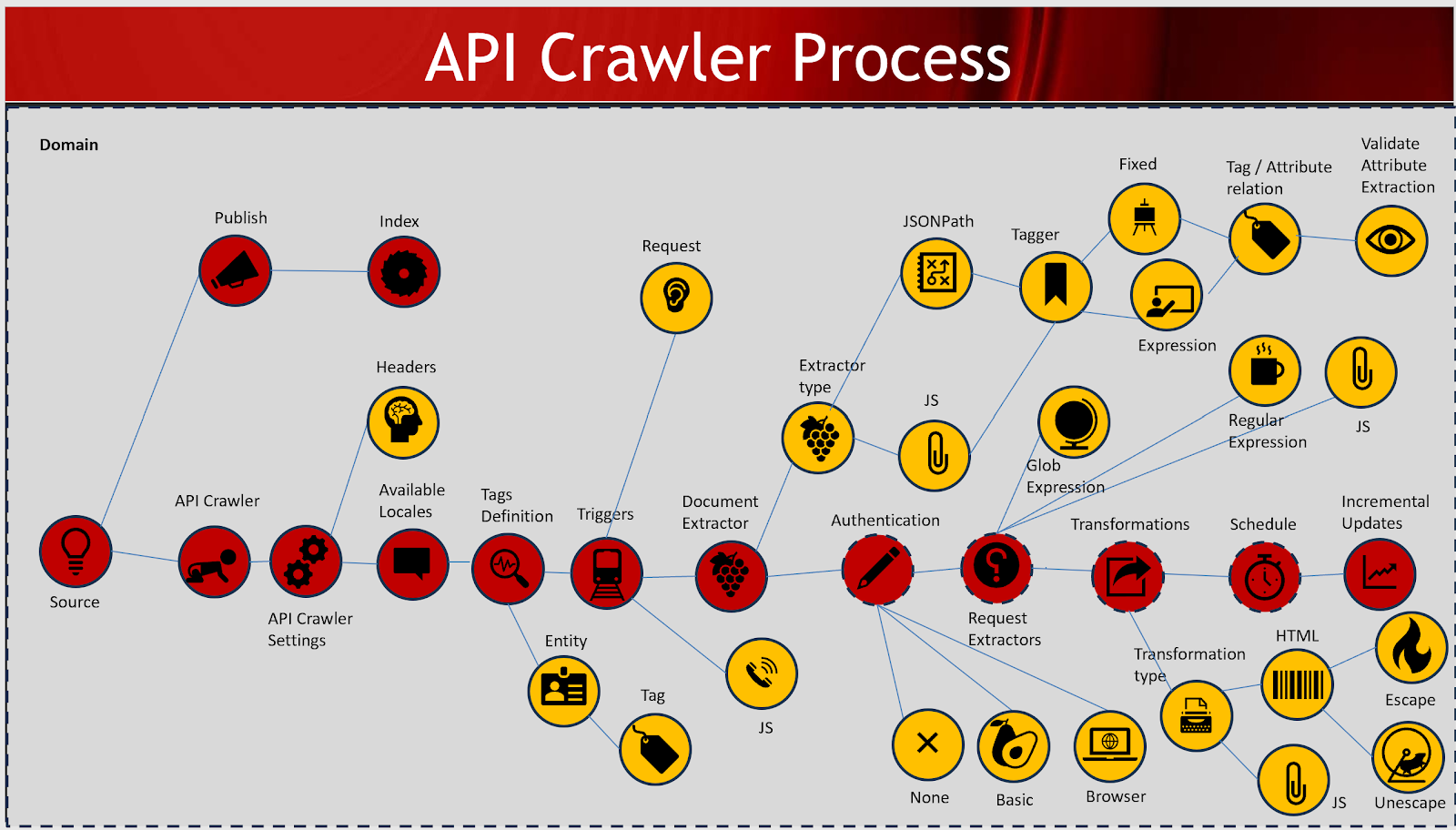
API Crawler overall process
.NET Core/EF Core/Swagger et al
Since I had SQL Server in my machine, the API setup was all about updating the connection string and kick-starting EF Core to create the database via update command in package manager console. Swagger was then accessible:

GET Endpoint response:

Expose local .NET Core API as public url
Once I could see the swagger page running locally, for the sake of it, I wanted to setup ngrok since ngrok Urls are publicly available. If not for this scenario, they could be useful utility for some other scenarios. So, I downloaded ngrok for windows and unzipped to find ngrok.exe. I safely stored this exe in c:\projects\ngrok. Hereon, I decided to run ngrok.exe from this folder. One issue I faced with ngrok was, it was quarantined by my windows security as a virus. As a result, I couldn't run ngrok-related commands. Once I allowed the exe on my laptop, I didn't have any more issues:
Program 'ngrok.exe' failed to run: Operation did not complete successfully because the file contains a virus or potentially unwanted softwareAt line:1 char:1
Trojan:Win32/Kepavll!rfn virus threat


Since i use a free version of ngrok, I get the following message when I access the public endpoint via browser:


Scenario:


The Sitecore Search documentation covers details about how to setup an API crawler but since this a practical scenario, I'll post images of the important areas I setup for the crawler to work with the GET student API.



Although all entity tags are added by default, the one for our need is the student tag in the list.


Request Extractor JS Function:

////
////
Note that if you don't pass the headers key/value like above, the custom attributes related to student won't be picked for indexing and you might see weird results in the attributes as follows:

This is because the header isn't passed in the request extractor, the json data is not available for the document extractor and instead, you are probably seeing some rogue code.
Note that there is validate option to check what gets returned as part of request extractor function and I raised a support ticket to fix the typo for Returned Urls -
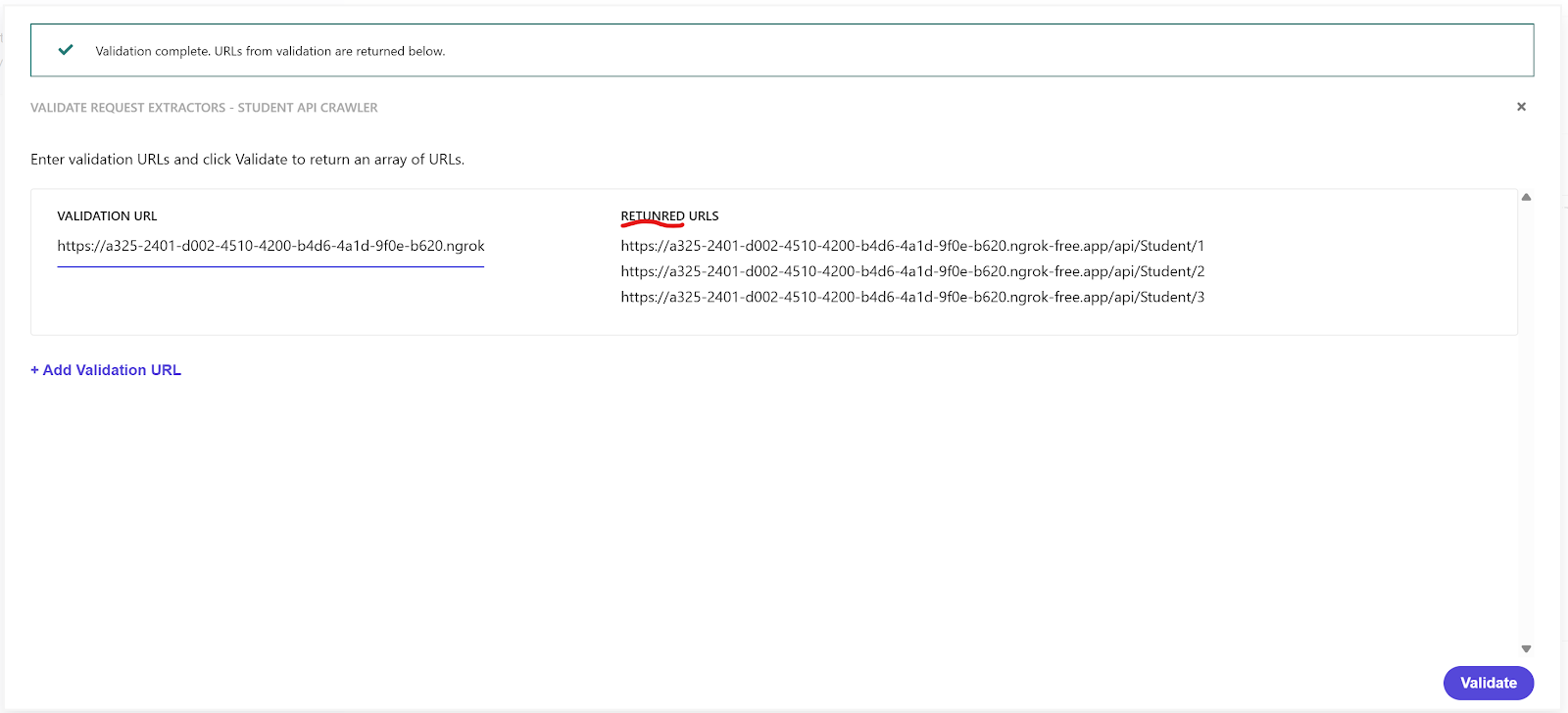

Document Extractor section:

Taggers section:

Taggers JS Function:
/////
/////
Very useful checkbox to trigger indexing as part of publishing the source crawler setup:

With all the plumbing in place, you must be able to see the records separately indexed in the content collection. Here I've juxtaposed one indexed document from Sitecore Search and the corresponding record in the REST API GET endpoint is visible in the adjacent browser.
End-result:
Sources list:
Content Collection:

Error and resolution list:
Error-1:
- Error crawling trigger request
- Validation Error: The number of indexed documents should be bigger than 0
Situation-1:
Clicking View details button opens up the following error:
Error crawling trigger request
Cause: parse " https://ddc3-2401-d002-4510-4200-c43a-6cc4-e2d4-8429.ngrok-free.app/api/Student": first path segment in URL cannot contain colon

Cause/Resolution:
This error occurred after publish and when crawling wasn't successful. In my case, the url in triggers section had a leading space. Once i removed the same and published, I didn't receive the above error.

- Validation Error: The number of indexed documents should be bigger than 0
Situation-2:
Clicking View Details opens up the following error:
Javascript error: Error crawling request
Cause: Error: Expected an array but got: undefined
Cause Location: functionCode.js:4:4
Cause Stack: Error: Expected an array but got: undefined at extract (functionCode.js:4:10) at wrap (script.js:35:30) at functionCall:1:1
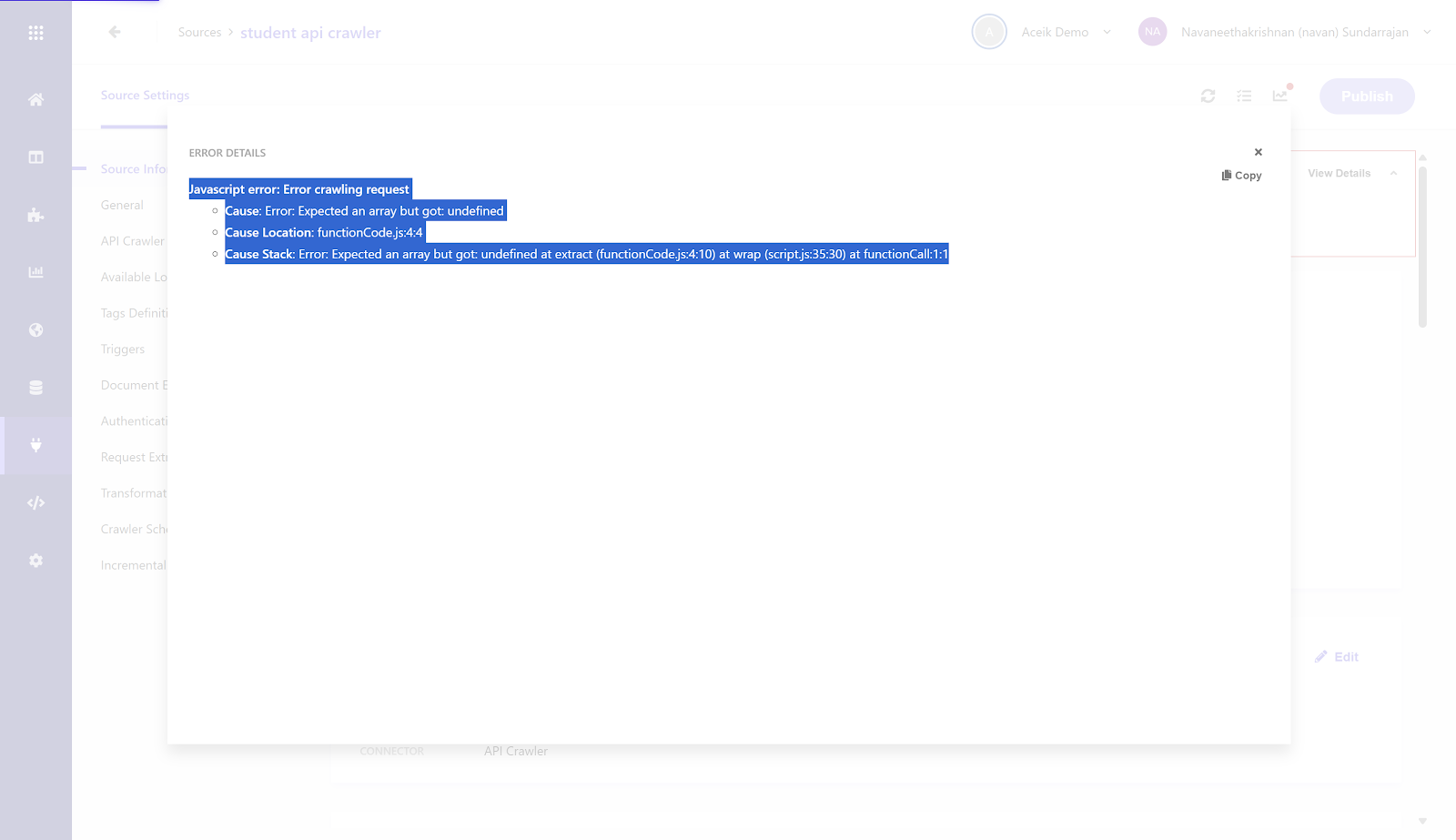
Cause/Resolution:
In the triggers section, the header ngrok-skip-browser-warning wasn't sent as part of triggers. Add the same and publish for a successful crawl.
Situation-3:
Clicking View Details opens up the following error:
- Error crawling request
- Cause: Message:'Something went wrong for url: https://ddc3-2401-d002-4510-4200-c43a-6cc4-e2d4-8429.ngrok-free.app/api/Student', Type:, Code:0, Data:map[cause:Not Found statusCode:404]

Cause/Resolution:
The actual local API wasn't running and ngrok public url was non-existent. Ensure the API is running, expose it via public endpoint, update relevant url(s) and publish to overcome the error.
Situation-4:
Clicking View Details opens up the following error:
Error crawling request
Cause: Message:'Something went wrong for url: http://localhost:5297/api/Student', Type:, Code:0, Data:map[cause:Get "http://localhost:5297/api/Student": dial tcp 127.0.0.1:5297: connect: connection refused statusCode:0]
Cause/Resolution:
Although the trigger section was pointing to the local endpoint, the error was as a result of the local endpoint not accessible for Sitecore Search. As a result, the local endpoint must be exposed as a public endpoint and the trigger must point to the public endpoint. Thereafter, publish the crawler to overcome the error.
Situation-5:
No View Details button but just the error:
- Validation Error: The number of indexed documents should be bigger than 0
Cause/Resolution:
Difference in casing of glob expression and actual url address as highlighted below:
Student vs student

Cause/Resolution:
This seemed a bit shady. It needs some digging to check if this case can be fixed at the REST api end. Or, if it is a genuine problem with glob expressions since there seems to be some case-sensitivity issues here. Anyway, based on my experience, ensure that the casing does match across all places like glob expression if present in url matcher for request extractor, document extractor and js code. For instance, in my case, the api call inside the request extractor js function worked fine only for "Student" with capital S. So, I ensured everywhere the Student had capital S. Thereafter, I published the crawler to overcome the error.

References:


Comments
Post a Comment